Getting into the production mindset
With Raptor, you can build models that run on production at ease without learning backend engineering. We do that by transforming your Python code into production artifacts, and then deploying them to production.
That being said, it's not a magic. And to unleash the power of Raptor, you need to get into "the production mindset".
It might sound a bit scary, but it's not. It's just a different way of thinking about your work, and it's not that hard to get into it. We found out that it usually takes a few days to get used to it, and then it becomes second nature.
The three pillars of the production mindset
The production mindset is based on three pillars:
- The transactional approach
- Be aware of the data you have available in production
- Be intentional about your code
The transactional approach
When we're building models, we're usually looking at historical data. We're trying to understand the past, and build models that can predict the future.
However, unlike in study, in production the application can't look back in the history books and go back in time - it lives in the present, and have access only to the "current state of the world" - the most recent "row" of the data.
Because of that, when we're calculating features we need to think about the data we have available, and work in the context of it in a transactional approach("row-level"), instead of a batch approach("dataset-level"). This tiny shift in the mindset can help us to build models that run on production.
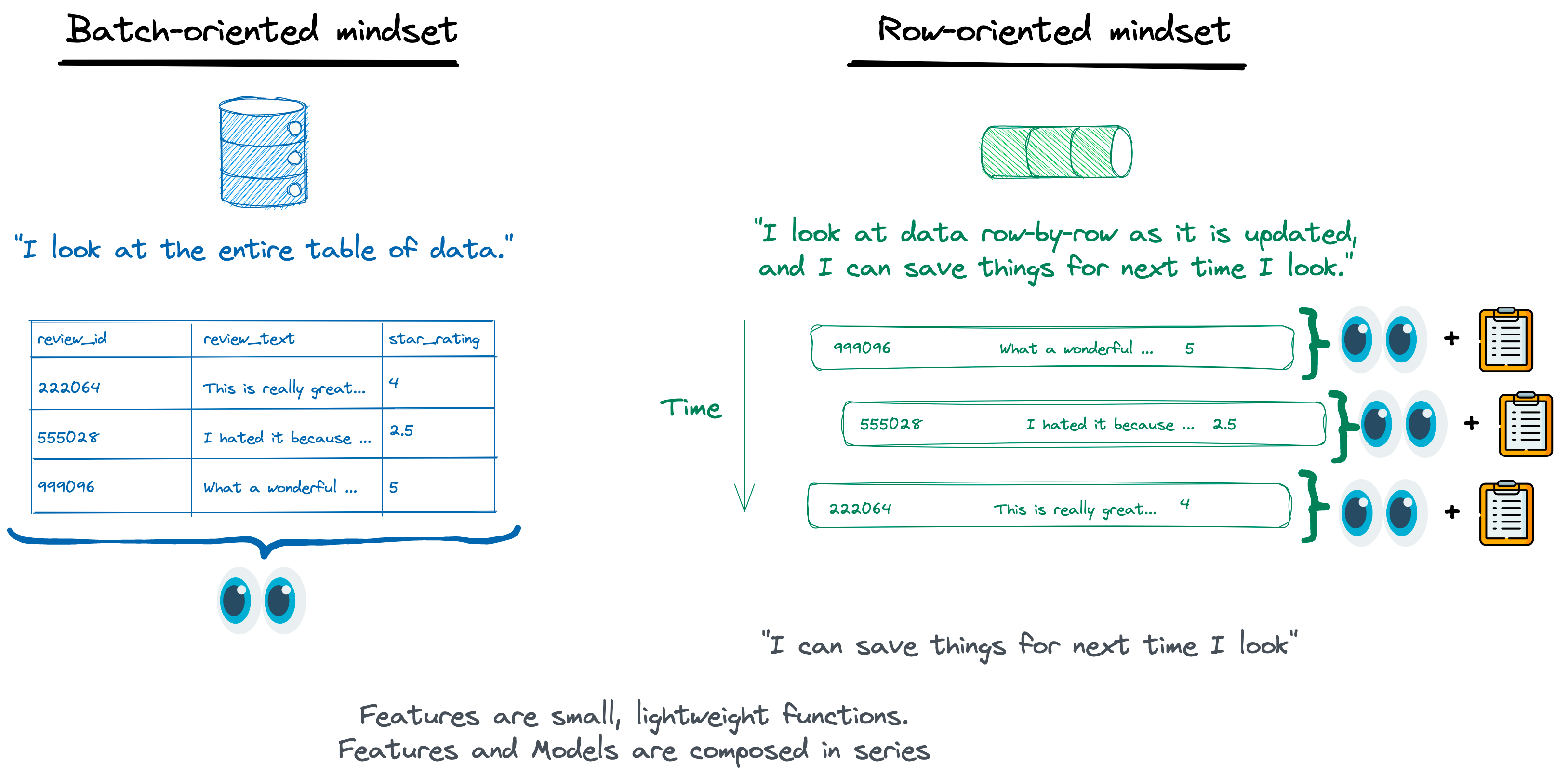 Illustration by Raptor's contributor Eric Peter
Illustration by Raptor's contributor Eric Peter
To do that, we write functions that calculate the feature values for a given "row" of data. For "complex" parts that
require more than one row, we can use the @aggregation decorator.
You should think of feature transformations as a function that calculates the feature value for a given "row" of
data. Complex cases are solved with decorators such as @aggregation or @keep_previous.
Be aware of the data you have available in production
When we're production-ready models, we should always remember that we're working with data that is available in production.
That means, that we should always use raw data from the datalake(aka snapshots of the production data), and use pre-calculated data as a last resort.
Prefer use the raw data from your datalake rather than the "views" from the data warehouse.
Be intentional about your code
This is going to be a short one, but it's important.
When you're writing code, you should always be intentional about it. You should always think about the code you're writing, and make sure that it's readable, maintainable, and easy to understand.
Avoid "dirty code" and write code that is easy to understand.
“Simplicity is not a simple thing.” ― Charlie Chaplin