From notebook to production
Transform your data science to production-ready models
Raptor compiles your python research code and takes care of the engineering concerns like scalability and reliability on Kubernetes.
Integrations
Easy to Use
You don't need DevOps or Backend Engineers to start writing production ready models, just used your beloved notebook as you're use to.
Focus on Data Science
Raptor lets you focus on the science, and we'll do the chores to productionize it.
Production-grade
Raptor handles all of the engineering concerns related to the deployment of your models.
Focus on the science
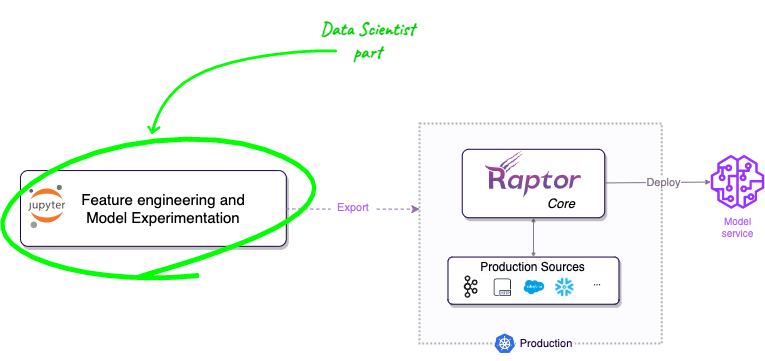
With Raptor, you can focus only on the research and model development, then export your work to production. Raptor takes care of the rest, including connecting to data sources, transforming the data, deploying and connecting the model, etc.
Install Raptor's LabSDK library
The LabSDK help you to get started on your local Notebook or IDE.
pip install raptor-labsdk
Create a Data Source
Represent your raw data as it looks in production and match it to the data you have locally.
@data_source(
training_data = pd.read_csv('transactions.csv'),
production_config = StreamingConfig()
)
class BankTransaction(TypedDict):
customer_id: str
amount: float
timestamp: str
Defining the data to use locally for training.
Feature engineering
Write simple python functions to create features, and the complex parts as decorators. Raptor will optimize the computation for production purposes.
@feature(keys='customer_id', data_source=BankTransaction)
@aggregation(function=['avg', 'min', 'max'], over='10h', granularity='1h')
def spending_delta(this_row: BankTransaction, ctx: Context) -> float:
"""the average, min and max spending delta in the last 10 hours"""
p, _ = ctx.get_feature('amount@-1')
return this_row['amount'] - p
Defining the feature, its keys, and the data source it uses.
Train production-grade models
Raptor will automatically create a production-grade model for you, and will optimize it for production purposes.
@model(
keys='customer_id',
input_features=['spending_delta+sum'],
input_labels=[amount],
model_framework='sklearn',
model_server='sagemaker-ack',
)
@freshness(max_age='1h', max_stale='100h')
def amount_prediction(ctx: TrainingContext):
from sklearn.linear_model import LinearRegression
df = ctx.features_and_labels()
trainer = LinearRegression()
trainer.fit(df[ctx.input_features], df[ctx.input_labels])
return trainer
Defining the inputs and labels for the model.
Export your work
Export your work to a git repository, and let the DevOps team do the rest. Just like every other project.
amount_prediction.export()