How does Raptor work?
This section is considered an advanced topic, and it's not required to read it in order to start building production-ready models.
Since most of the "heavy duty" work, and the complex parts are related to the "production running" - this section is mostly focused on it, and on the "Raptor Core" component.
Raptor is extending Kubernetes to serve features and models in a production-grade manner. It's implementing the "Kubernetes Way," which advocates for writing the desired state and allows you to focus on writing the business logic. Raptor takes care of the engineering concerns of implementing the "desired state" by managing and controlling Kubernetes-native resources such as deployments to connect your production data-sources and to run your business logic at scale.
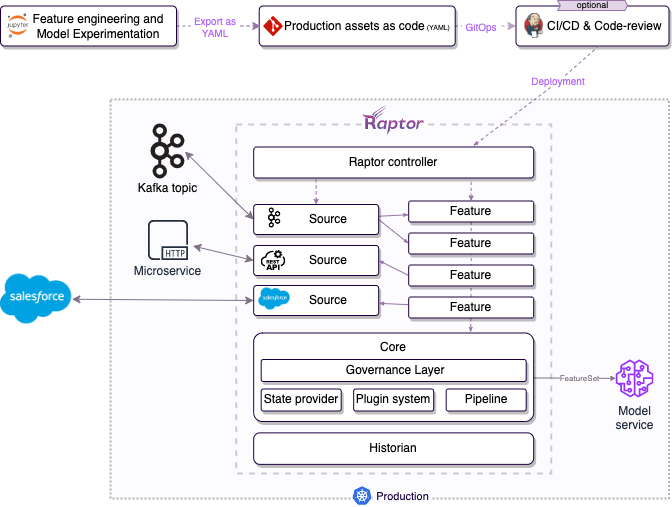
To achieve that, Raptor must understand the logic of your asset and create the engineering setup required for the production version.
Raptor Assets are usually stored in Git, like any other Kubernetes' manifest you have in your organization. This approach carries benefits such as review and comparison for every change, an ability to see previous versions, etc.
Feature and Models Definitions only become available after Raptor Operator spins off the necessary compute, connections, and storage resources needed for it. We recommend using your CI/CD to deploy the Feature Definitions to the Kubernetes cluster, as you do with any other Kubernetes resource. Applying your DevOps policies like code-review or "staging first" can be very useful and can finally make DS resources an integral part of your RND.
After the Assets have been deployed to your cluster, Raptor Operator automatically discovers them and uses the relevant Builder to configure the resources needed for the Feature. Such resources include DataSource to external sources, storage resources, and compute resources.
Finally, after the Assets are deployed, you can access the Feature Values and Model predictions using the REST or gRPC APIs.